Method
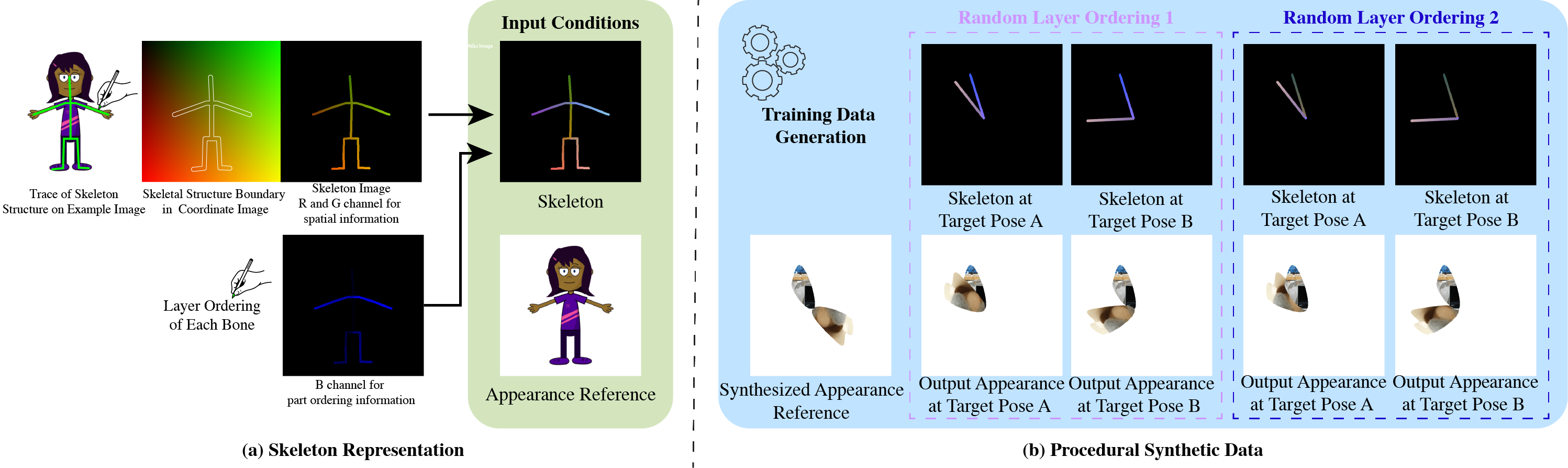
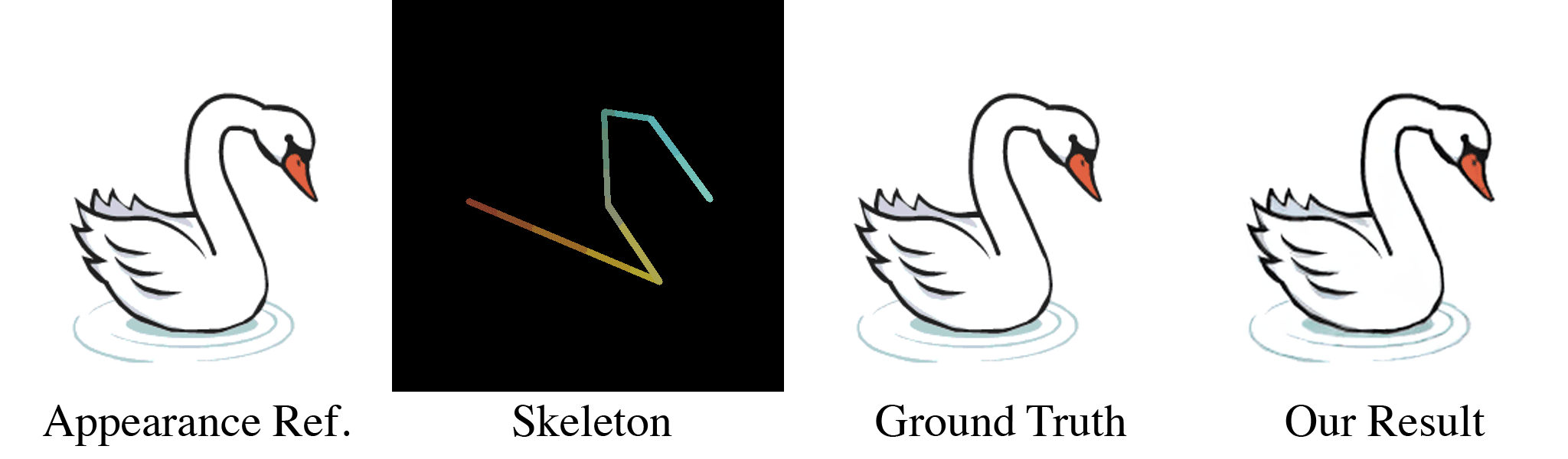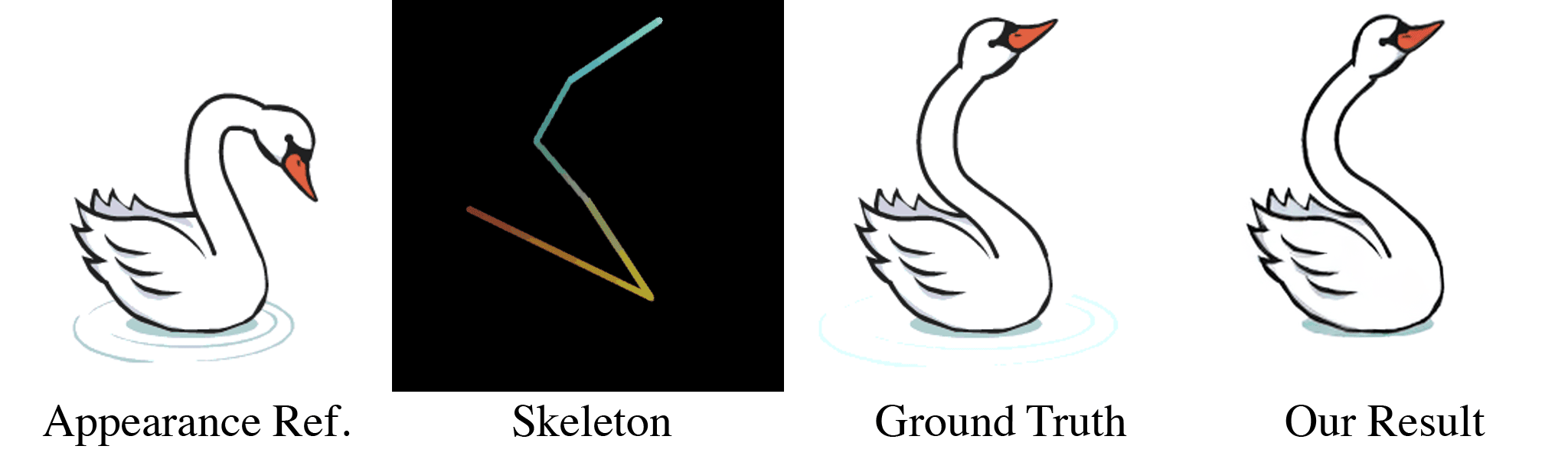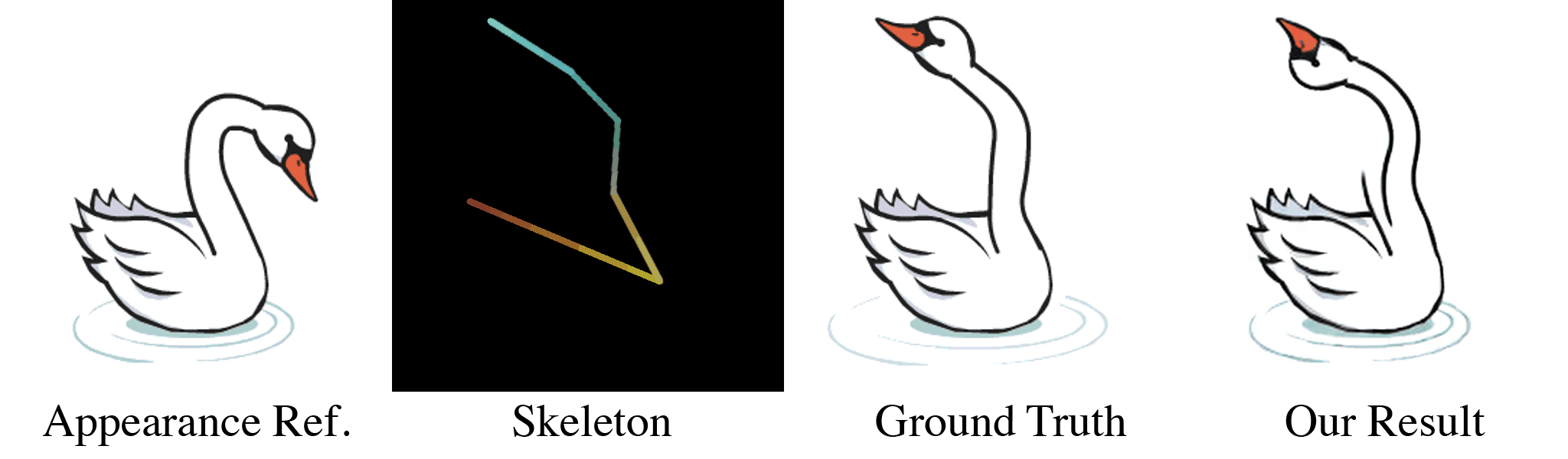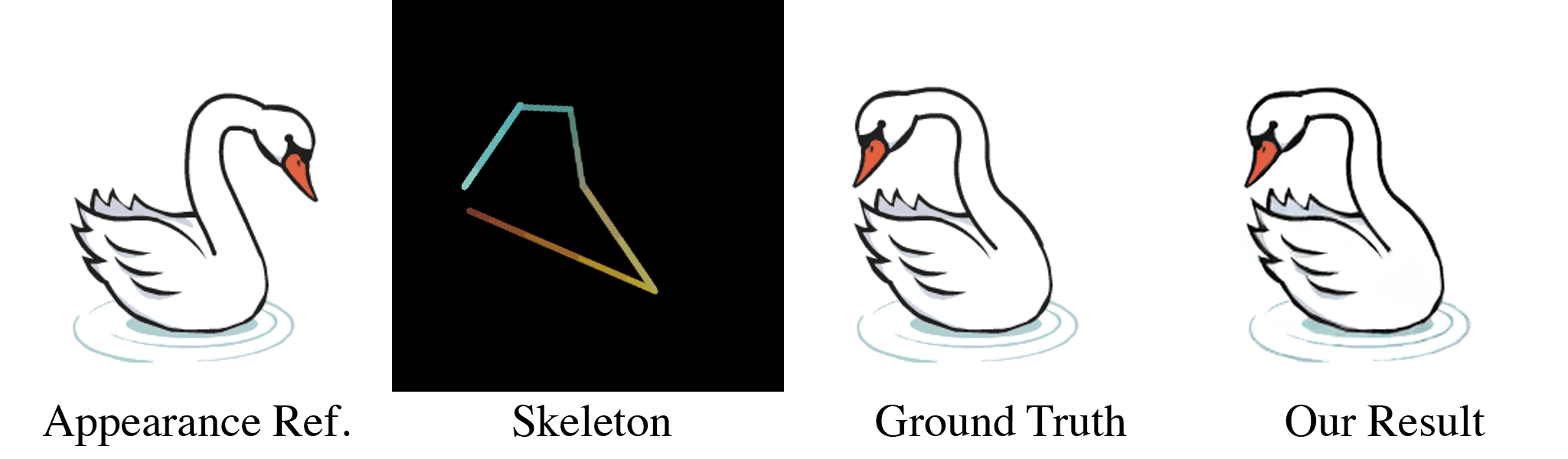
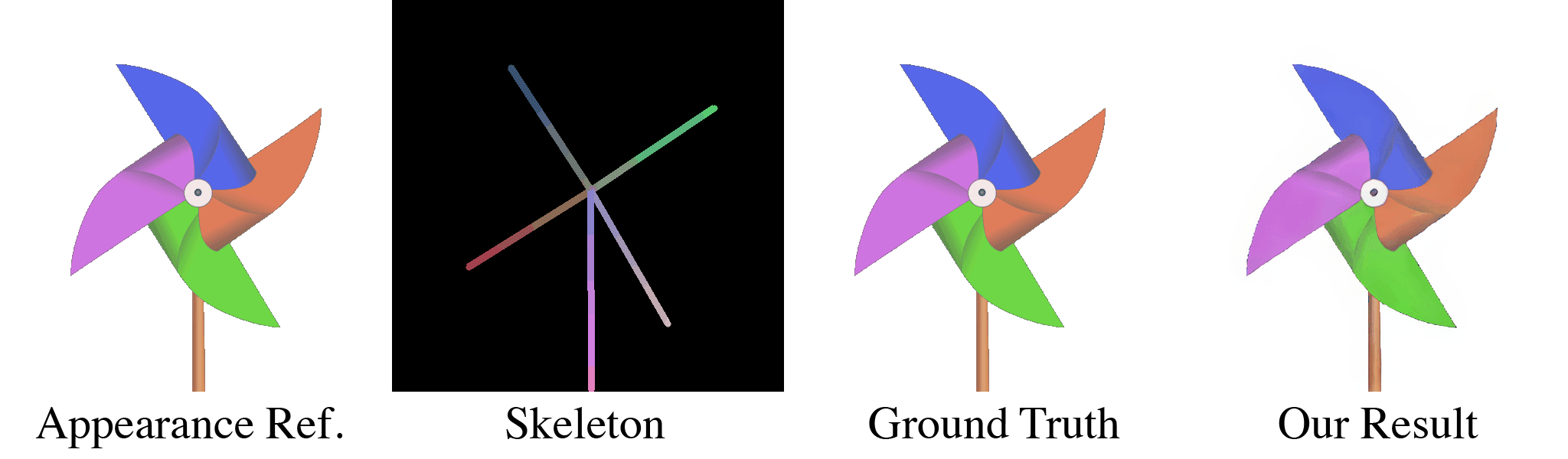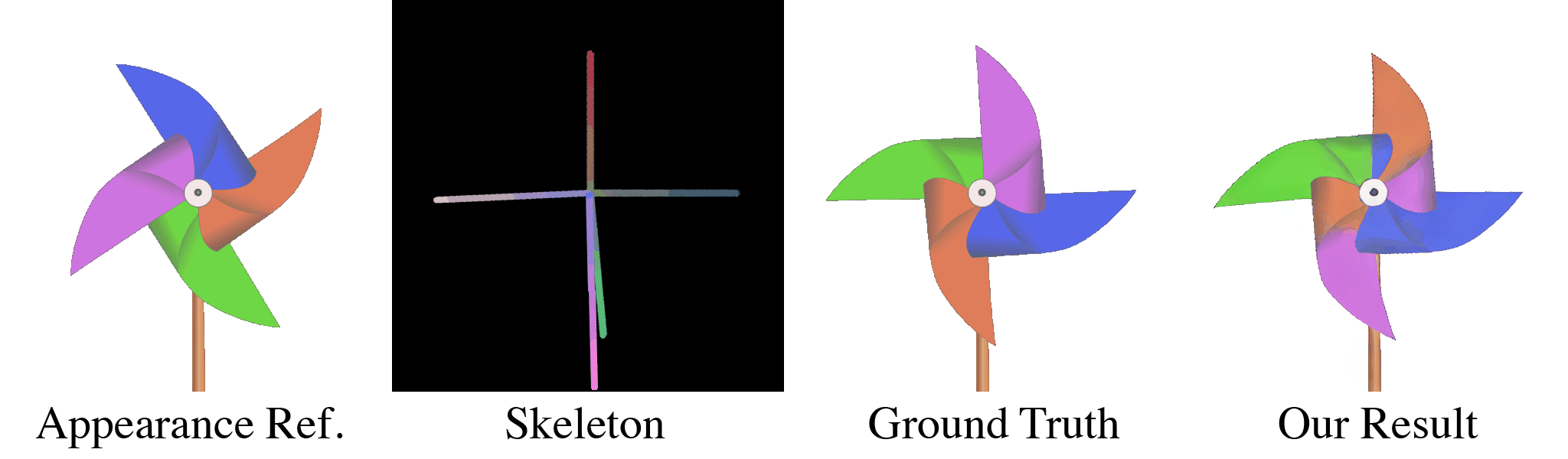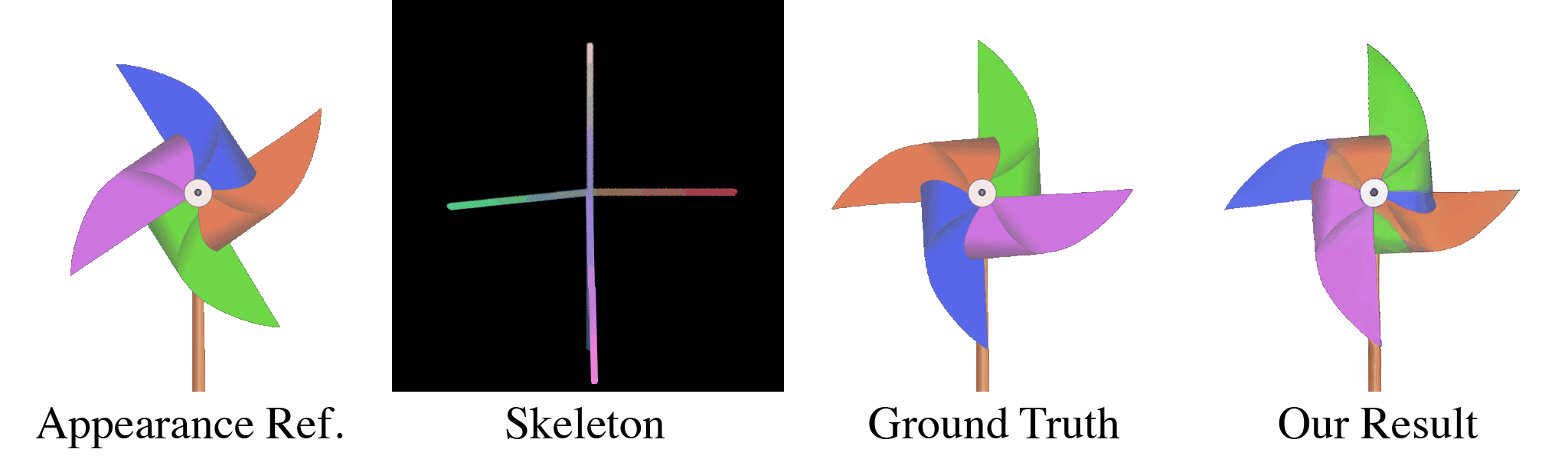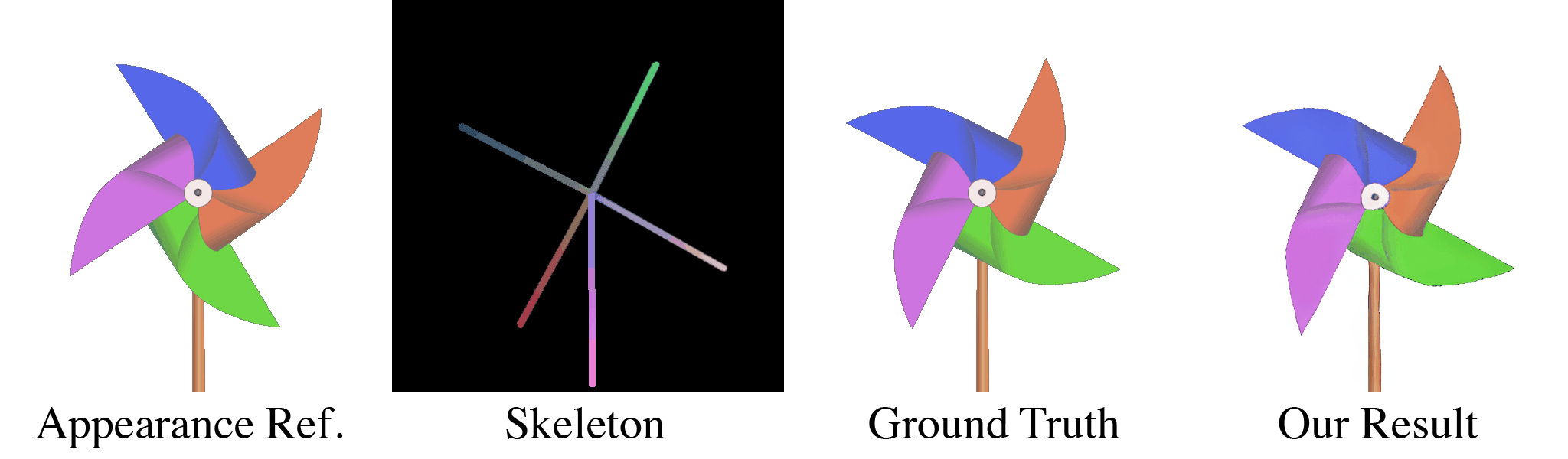
(a) Our model takes in an appearance reference image and a skeleton image as inputs. (b) For the first training stage, these are randomly generated through our data pipeline. With almost infinite possible combinations of texture, shape, and topology, our synthetic dataset is more challenging than any real-life datasets, which forces our model to learn the correct binding and deformations. Our skeleton representation for this wide range of topologies is also unique: in the Red and Green channel of this RGB image, we color pixels according to their $x$ and $y$ coordinates. When a user specifies a new target pose, this skeleton is transformed accordingly, which means that the value of pixels in the target skeleton image now refer to source coordinates in the starting rest pose. We use the Blue channel to embed layer ordering of each part of the body, which is crucial for characters that contain parts of different depths. For each appearance we train the model multiple target poses and layer orderings, as shown in the two dashed boxes in (b). When the new pose causes occlusions as in the two left columns, the supervising ground truth appearance is different when the order changes. Thus, our model is forced to understand the influence of layer ordering to appearance.